

At Quinyx, we help customers daily with all sorts of questions around the use of algorithms in workforce. A major goal of our algorithms is to improve employee satisfaction and happiness by better predicting when an employee is required and how to make fair schedules that determine who works when.
In our daily discussions, we see a number of things that can lead to suboptimal or even bad results and therefore we decided to create a series of articles that each highlight one of the many best practices when it comes to the use of algorithms for labour demand forecasting and the creation of schedules.
Today, we will talk about Best Practices in Workforce Optimization Part 2 – How to not estimate labor standards.
Demand Forecasts, so what?
In my previous article, I wrote about heuristics in demand forecasting and scheduling. Now that you have thrown those heuristics out of the window, you can finally make highly accurate demand forecasts. But what now? Demand forecasts give you proper insights on what future demand will be, but it creates no value when not using that information correctly. Remember: knowing that you’ll sell 30 milkshakes between 18:30 and 18:45 in the middle of rush hour doesn’t tell you how many milkshake handlers and cashiers you need to perfectly cover your demand and not lose potential sales due to seemingly never-ending lines.
In order to translate forecasts into shifts that cover demand, you need labor standards. Labor standards within WFM appear in many different forms, and we utilize them to know how long work takes when a certain task needs to be executed. For example, for each milkshake you sell you need 2 minutes of a milkshake handler and 1 minute of a cashier.
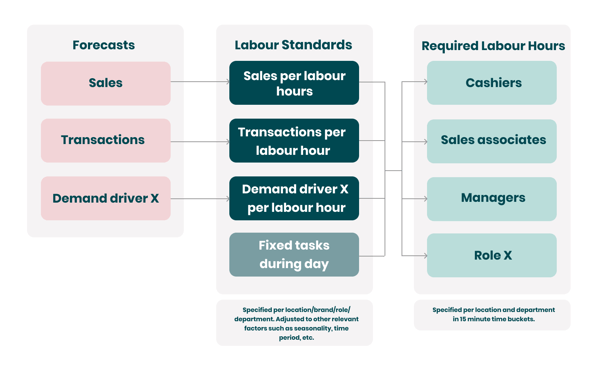
Labor standards can be made per demand driver, giving you an even more accurate estimation of how many of each employee type you need given a certain time frame.
One thing which pops up regularly when we work with customers is that we hear that they do not know what their labor standard is or should be. Then we are requested to help out setting the labor standards and there are several ways to do it, so let’s break them down.
Lots of data? Yay! Don’t use it.
There are different ways to define labor standards. Here are the most common approaches we follow ourselves or have seen customers following:
- Estimating labor standards by using traditional methods such as time and motion studies (using a video camera to look at activities and using those time measurements as a labor standard) or using more modern techniques and crowd sourcing the measurement.
- Utilize the best known labor standard and sanity check the results by multiplying a demand forecast by the estimated labor standard and matching it to existing rosters.
- Reverse engineer labor standards by calculating roster hours per demand driver. In other words take the hours people work and the amount of items sold or number of transactions to get to a ‘sales per labor hour’ metric
Let’s start with what the worst possible approach is: number 3. The third method will lead to a situation where current rosters with existing problems (like lots of over-rostering) will lead to a labor standard that will therefore uphold this bad practice. It also gives a false sense of security that the labor standard fits the rosters.
The other problem is that this approach will not take into consideration any productivity unless that is added as an additional percentage. To clarify, if the labor standard of making a milkshake is 2,5 minutes it would mean that if you expect to sell 10, you will need 25 minutes. However if you reverse engineer you might see that during one hour you sold 6 and another hour you sold 4. This would indicate that labor standard is 10 or 15 minutes, which is not true in both cases. This is because the unproductive time is already part of the calculation here, which you get no clear view on when you reverse engineer. In the original example we have 35 minutes of unproductive time, but that fact can be used in the rostering process to decide whether an hour of staff is required or not. The third approach is often taken because an organization indicates they are not capable of providing a labor standard, but it’s not the best way to actually define it.
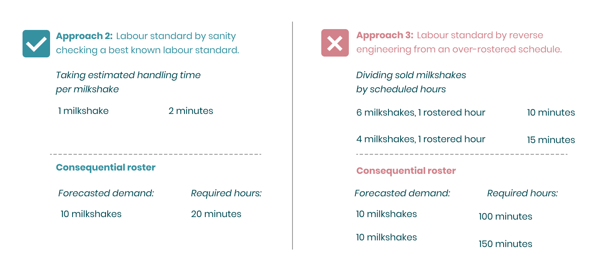
Sanity checking from an estimated handling time will most likely lead to a more accurate labor standard. Here you can see that you run the risk of over-rostering by reverse engineering it from past schedules that were over-rostered to begin with.
For organizations with more resources at hand, there’s always an option to go with approach 1. This approach is more time and money consuming, but you’re assured to get highly accurate labor standards defined specifically by your own business environment. Sometimes, however, organizations simply can’t or won’t wait or spend those resources. This is particularly the case when considering you could save more costs and lose less sales, and of course improve employee satisfaction and compliance, the sooner you start making optimized schedules. And that’s where approach 2 steps in.
Check one, check two, check…
Approach 2 is an iterative way to define labor standards by taking an existing labor standard and improving it as you make schedules with this standard. Let’s take a practical example: Say you processed 100 transactions on a day and you, based on experience, know that the average time per transaction is 10 minutes. Multiply this labor standard times the number of transactions to work out an expected number of labour hours. This could either lead to massive under or over rostering compared to actual rosters, which can then be used as a guidance to tweak the number up or down. When this is done, use an expected number of transactions for a new day or week to work out the required headcount and accompanying shifts. These results can be sanity checked by an expert to see if they are on the right track. This loop of improving the labor standard then goes on until the schedules using the latest version of the labor standard is up to, well, your own standards.
You might say that this sounds similar to approach number 3. There are similarities, but the big difference is that we start with an actual labor standard in approach 2. Reverse engineering based on rosters might sound like a good idea, but why not use the opportunity to work out the actual labor standard and avoid the under and overstaffing as shown in approach 3.
Slow but steady does win the race sometimes
Option 3 is the typical approach because of time pressure or certainty to get results produced. It is always an option of course, but why risk it and take a bit more time to tackle the problem in a structured way. Approach 2 is the most accessible way to start using labour standards relatively quickly. Sometimes slow and steady does win the race and the business improvements end up being more realistic and better than trying to use a short term solution.
Labor standards play a crucial part in making sure a business knows how many minutes of work to schedule based on an expected demand. It is an important pillar of the roster next to having an accurate forecast. Labor standards allows you to automatically generate the optimal shifts with correct breaks and assigning them according to the preferences of staff. Don’t gamble on the labor standards, the turtle does win sometimes.
